
В этом гайде мы расскажем о том, как создавать и оптимизировать экспертный контент. Для этого выражения XPath мы будем использовать в сочетании с инструментом для SEO-аудита Screaming Frog. Об этой связке недавно подробно рассказал Брэд Маккорт, а мы адаптировали его советы для рунета. С помощью этих инструментов мы соберём информацию для подготовки материалов, которые будут сполна отвечать на вопросы посетителей.
Главная задача тут – найти и обработать всё, что действительно беспокоит покупателей. Для этого мы обратимся к разделам Q&A на крупных сайтах. Зачастую они представляют собой настоящий кладезь проблем, с которыми сталкиваются заказчики. Связка XPath с краулером позволяет быстро собрать и получить эту информацию в удобной для работы форме. Затем её легко можно использовать для создания экспертного, авторитетного и вызывающего доверие контента.
XML Path (XPath) – это язык запросов, разработанный W3 для навигации по XML-документам и выбора указанных узлов данных. С помощью выражений XPath можно быстро собирать любые сведения с сайта, между страницами которого существует согласованная связь. Этот язык отлично подходит для извлечения общедоступной информации из исходного кода, в том числе и вопросов и ответов со страниц крупных сайтов. Что для этого нужно? Достаточно базового знания структуры XML- и HTML-документов. Именно поэтому XPath – такой полезный инструмент для сеошника, знаком он с языками программирования или нет. Разберёмся, как это работает на конкретном примере.
Как уже было сказано, в нашем примере мы будем использовать Screaming Frog. Это самый экономичный вариант, позволяющий сканировать до 500 URL, не покупая лицензию. Если этого вам недостаточно, вы можете приобрести её и сканировать любое количество адресов. Можно использовать другие решения, в числе которых Botify, DeepCrawl и OnCrawl, так как все они позволяют извлекать данные из исходного кода.
Предположим, нас интересуют реальные вопросы, беспокоящие покупателей триммеров. Где их взять? Возможно, вы найдёте их на каких-то других сайтах – эта инструкция универсальная и подойдёт практически для любых вариантов, – но мы за ними пойдём в известный интернет-магазин.
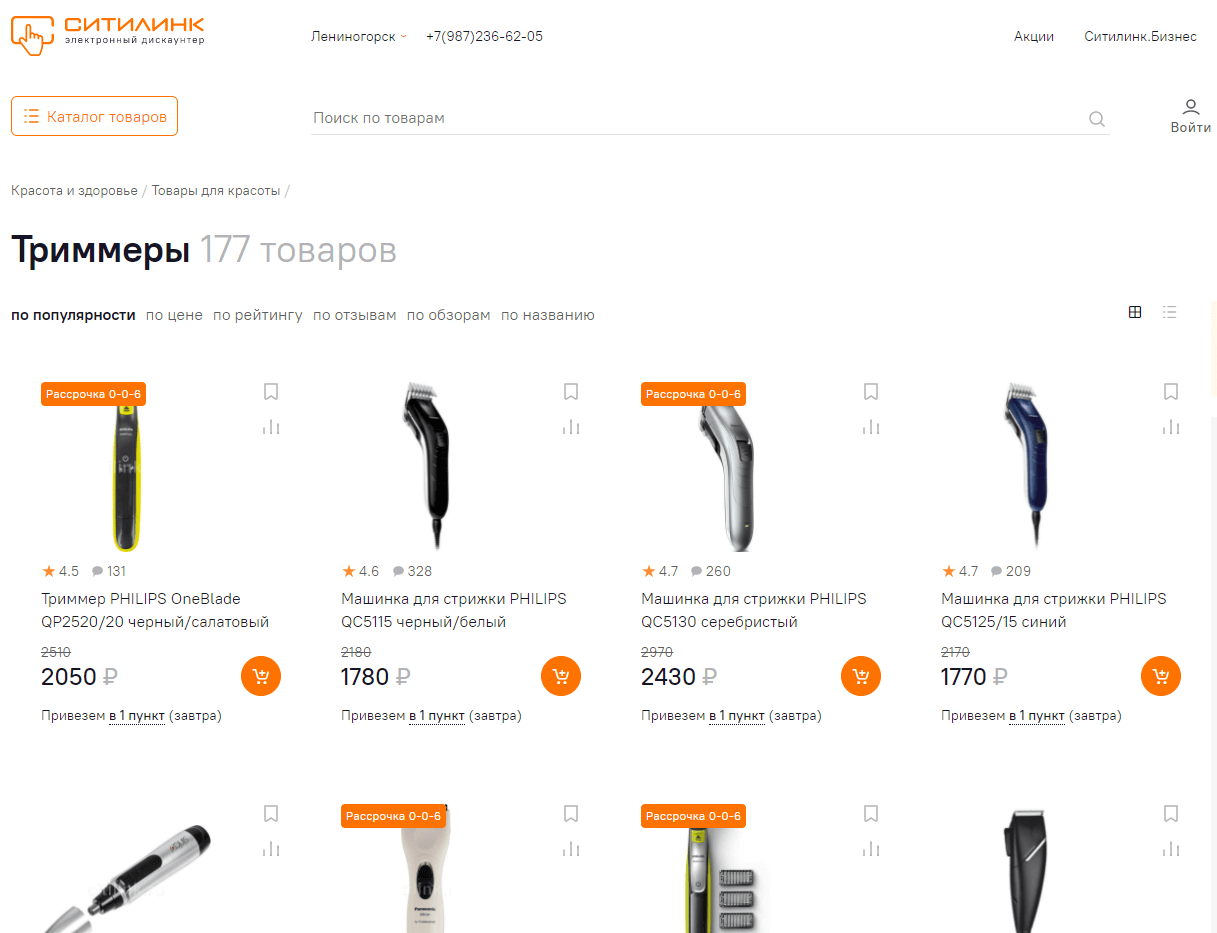 В первую очередь нам нужно собрать ссылки на нужные товары. Если вас интересуют вопросы, относящиеся к конкретным моделям, вы можете сформировать список соответствующих URL, воспользовавшись поиском по сайту. Мы для примера возьмём первые восемь популярных позиций – для этого просто копируем адреса прямо из каталога.
В первую очередь нам нужно собрать ссылки на нужные товары. Если вас интересуют вопросы, относящиеся к конкретным моделям, вы можете сформировать список соответствующих URL, воспользовавшись поиском по сайту. Мы для примера возьмём первые восемь популярных позиций – для этого просто копируем адреса прямо из каталога.
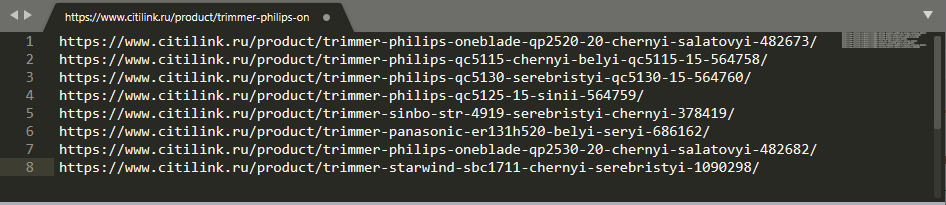 Теперь осталось доработать эти адреса таким образом, чтобы они вели на страницу с вопросами. Для этого заходим в карточку любого товара – о том, как их правильно оформлять, мы рассказывали в этой инструкции – и находим там ссылку на раздел Q&A. Переходим по ней и смотрим, как изменился URL. В «Ситилинке», например, к прежнему адресу добавляется "/vopros-otvet/".
Теперь осталось доработать эти адреса таким образом, чтобы они вели на страницу с вопросами. Для этого заходим в карточку любого товара – о том, как их правильно оформлять, мы рассказывали в этой инструкции – и находим там ссылку на раздел Q&A. Переходим по ней и смотрим, как изменился URL. В «Ситилинке», например, к прежнему адресу добавляется "/vopros-otvet/".
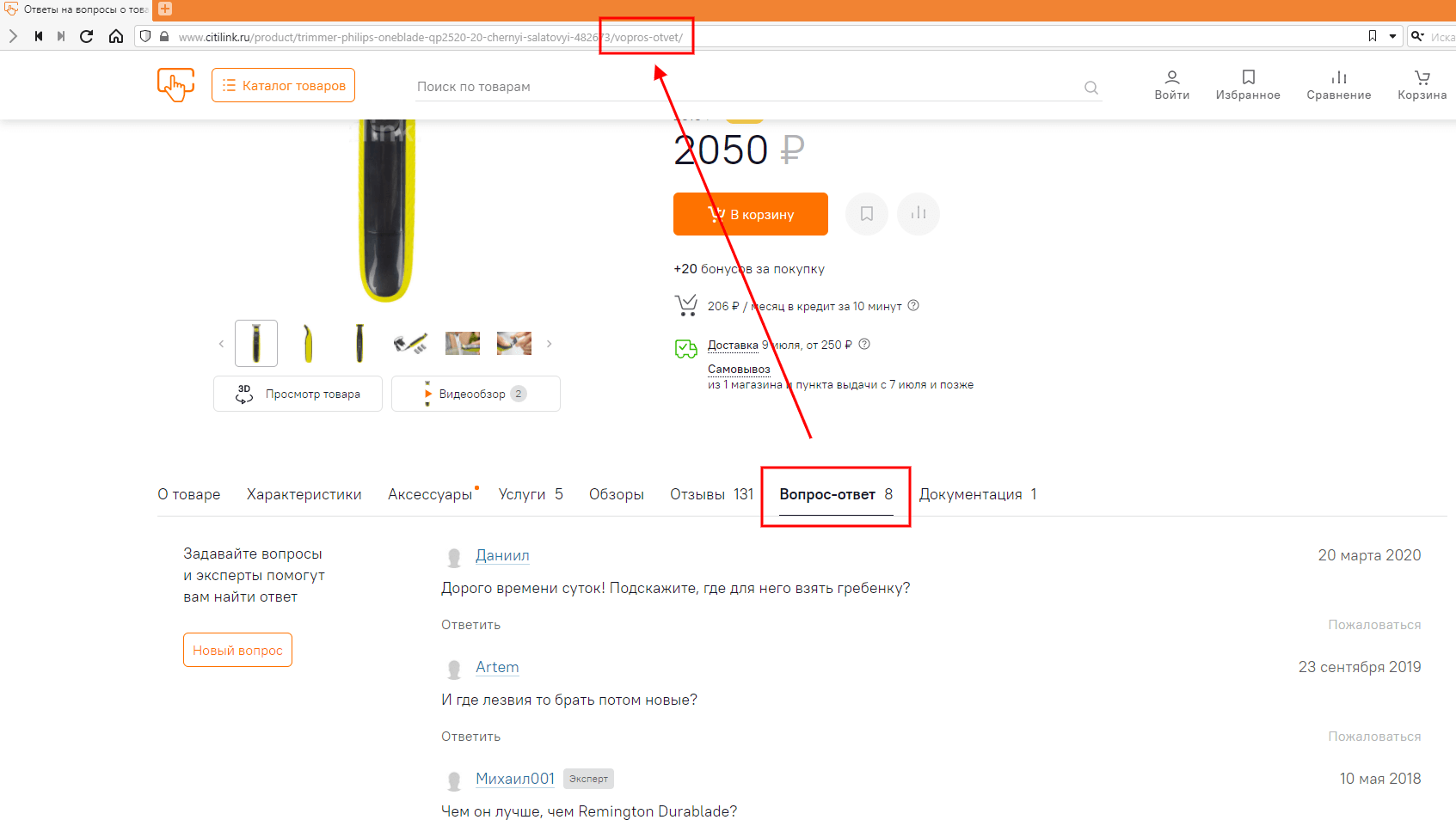 Этот текст нам и нужно добавить во все URL из списка. Получается следующая картина:
Этот текст нам и нужно добавить во все URL из списка. Получается следующая картина:

Чтобы краулер собрал вопросы с нужных страниц, «скормить» ему URL-адреса недостаточно – ему нужно объяснить, какая именно информация нам нужна. Для этого мы будем использовать выражение XPath. Сформировать его просто:
Для начала откроем любую страницу из нашего списка.
Теперь наведём курсор на текст любого вопроса, нажмём правую кнопку мыши и включим просмотр исходного кода. Вот, что получится:
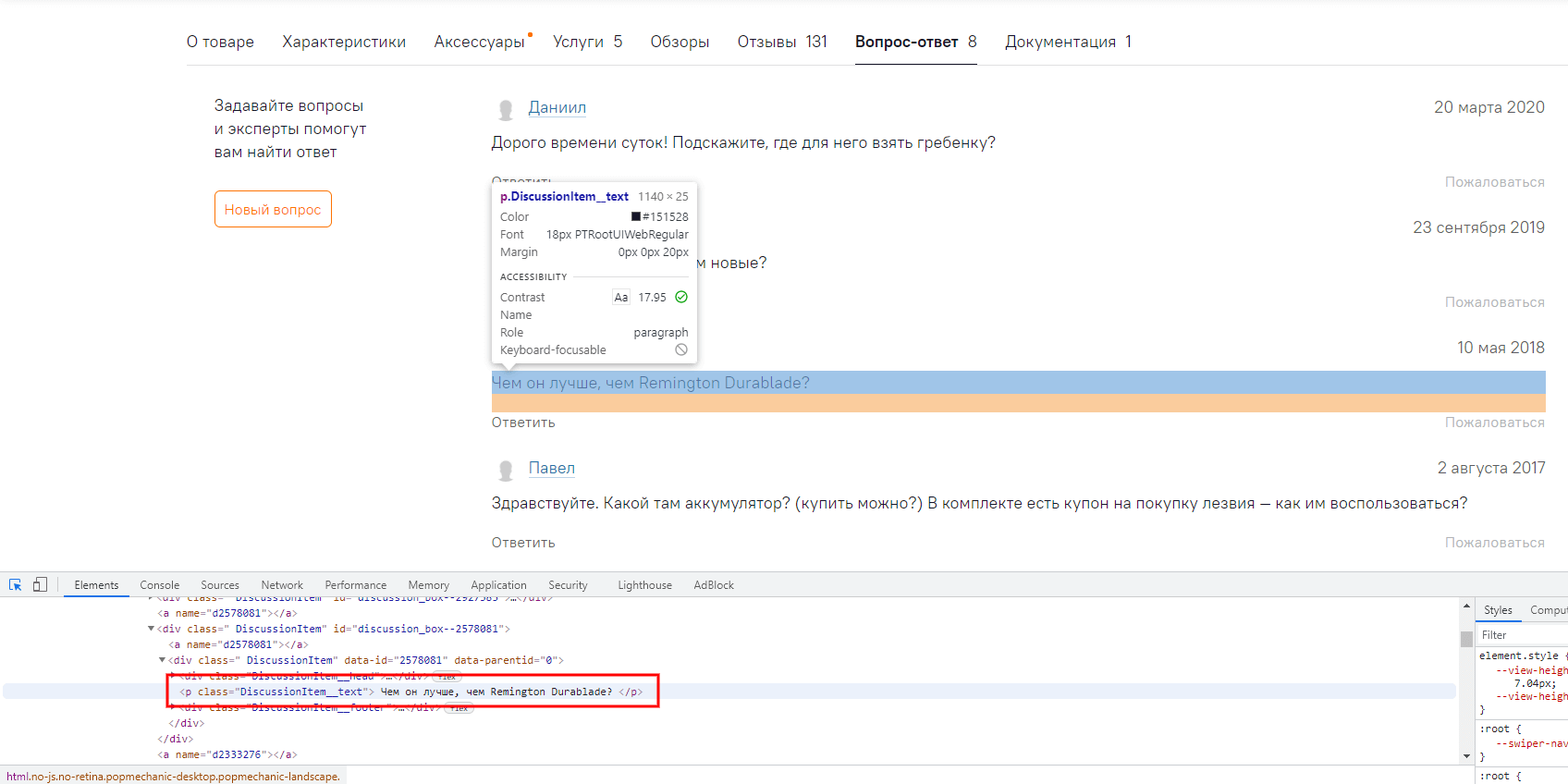
Тут важно обратить внимание на два момента: во-первых, на тег – в нашем случае
– и, во-вторых, на класс – «DiscussionItem__text».
Зная эти две вещи, для сбора вопросов на странице краулером формируем следующее выражение: //p[@class="DiscussionItem__text"].
Что в нём за что отвечает?
в исходном коде, а поскольку этот тег отвечает за каждый абзац текста на странице, то нам нужно как-то конкретизировать запрос.
Для получения текста внутри тега нам потребовалось бы выполнить ещё один шаг, но тут Screaming Frog всё сделает за нас, так что сразу перейдём к его настройке.
В первую очередь, в краулере нужно задать настройки извлечения. Для этого в меню выбираем Configuration – Custom – Extraction.
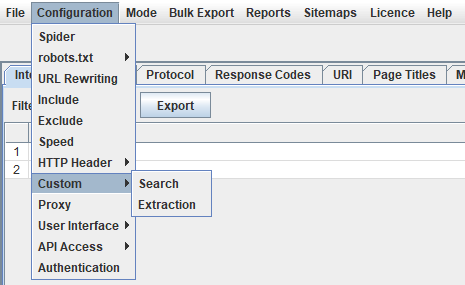 Далее в нашем случае достаточно добавить настройки, как на скриншоте ниже.
Далее в нашем случае достаточно добавить настройки, как на скриншоте ниже.
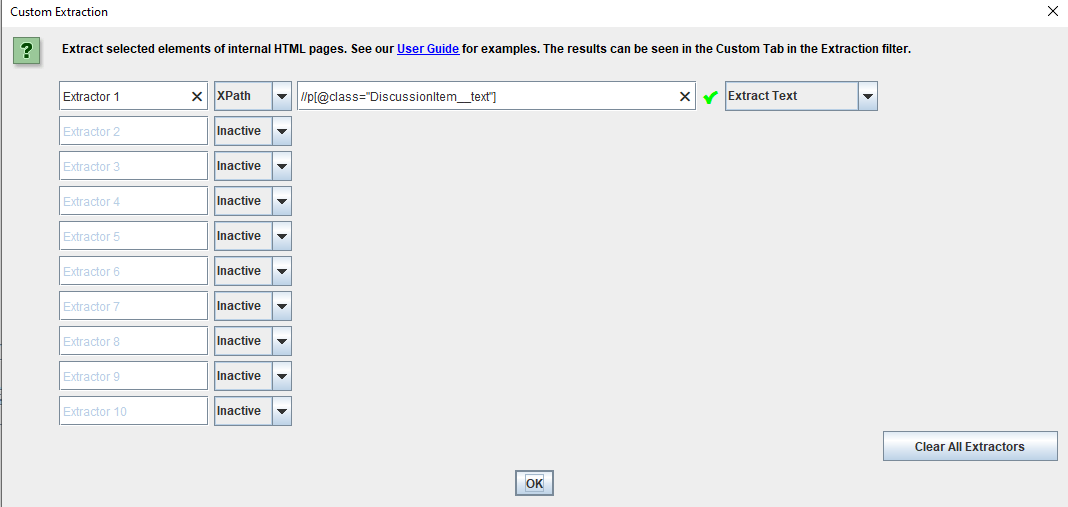 Если потребуется, в этом окне можно задать и другие настройки, в том числе:
Если потребуется, в этом окне можно задать и другие настройки, в том числе:
с классом «DiscussionItem__text», мы выбираем «Extract Text».
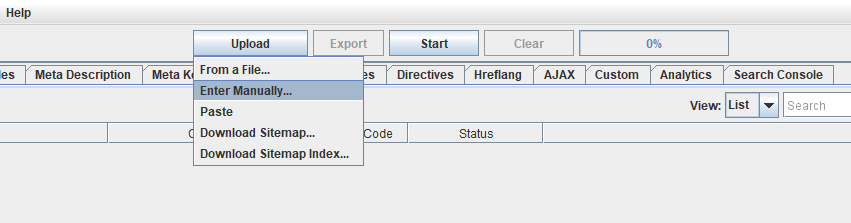
Пришло время заняться главным – собрать вопросы. Для этого в меню Mode в Screaming Frog измените режим Spider на List. Далее нажмите Upload – Enter Manually, добавьте в открывшееся окно ссылки на страницы, с которых вы хотите собрать вопросы, и нажмите Next.
 Дело за малым – кликаем Start и ждём окончания краулинга. По завершении работы Screaming Frog в разделе Overview выберите Custom Extraction – тогда вы увидите столбцы с собранными на нужных страницах вопросами и ответами.
Дело за малым – кликаем Start и ждём окончания краулинга. По завершении работы Screaming Frog в разделе Overview выберите Custom Extraction – тогда вы увидите столбцы с собранными на нужных страницах вопросами и ответами.
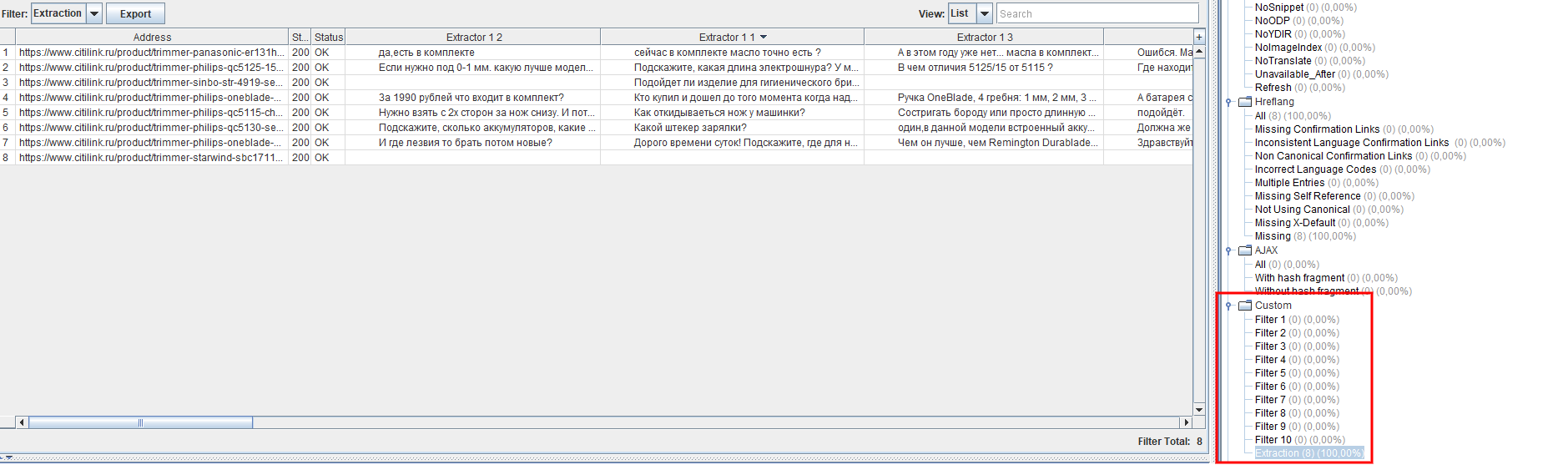 Чтобы с было удобнее работать, выделите весь контент в этом окне, а затем вставьте его в редактор таблиц. Вот лишь часть вопросов, которые нам в итоге удалось получить:
Чтобы с было удобнее работать, выделите весь контент в этом окне, а затем вставьте его в редактор таблиц. Вот лишь часть вопросов, которые нам в итоге удалось получить:
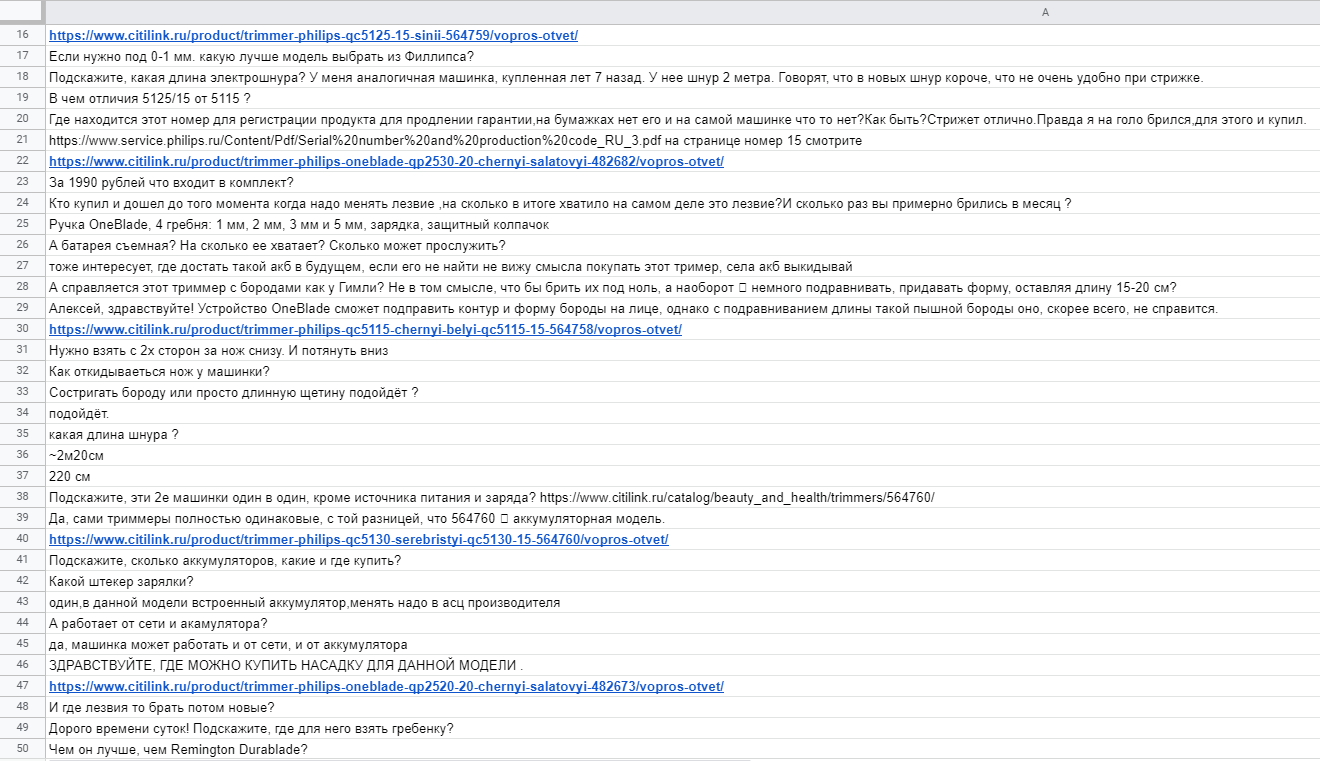 Таким образом можно быстро и в удобной форме собирать тысячи вопросов реальных покупателей о товарах и ответов на них. Очевидно, когда такие данные оказываются под рукой, их легко можно использовать для улучшения контент-стратегии.
Таким образом можно быстро и в удобной форме собирать тысячи вопросов реальных покупателей о товарах и ответов на них. Очевидно, когда такие данные оказываются под рукой, их легко можно использовать для улучшения контент-стратегии.
Для начала упростите себе работу с собранными вопросами. Их будет намного удобней использовать, если сначала вы разделите их на категории. В нашем примере «рубрики» вопросов могут быть следующими:
Всё это – только небольшая часть вопросов, которые беспокоят реальных покупателей при выборе товара. Такое глубокое понимание потенциальных проблем, которые могут возникнуть у пользователя при выборе триммера, использовать для улучшения контент-стратегии вы можете несколькими способами.
Самое очевидное, что мы можем сделать с полученной информацией – включить её в описание товаров или категорий. Таким образом, мы заранее ответим на вопросы, которые могут возникнуть у покупателей. Например, можно улучшить раздел «комплектация», дополнив его, а также расширить само описание товара, добавив в него подробные правила использования и сравнение с некоторыми другими моделями.
Не все вопросы можно включить в описание продукта, некоторые из них куда лучше подойдут для небольшого раздела с вопросами и ответами в карточке товара. Обратившись к нему, посетители смогут сразу найти там нужную им информацию – то есть, им не придётся задавать вопросы и ждать на них ответа перед покупкой. Вы также можете на свой страх и риск внедрить на эту страницу разметку FAQPage Schema.org. Зачем это нужно? Во-первых, чтобы получить расширенный сниппет в выдаче Google. Во-вторых, чтобы повысить вероятность ранжирования в блоках «Люди также ищут» (PAA). Нужно ли вам второе – решать вам: некоторые исследования утверждают, что количество показов после внедрения разметки FAQPage возрастает, а вот переходы из поиска, напротив, падают.
Ещё одна стратегия заключается в создании обширных руководств по продуктам или их категориям. В них могут быть описаны примеры использования, приведены сравнения с другими товарами и прочая подробная информация. В нашем случае мы могли бы посвятить такие руководства разным категориям товаров – например, машинкам для стрижки волос, триммерам для бороды и триммерам для усов.
В каждое такое руководство можно включать разнообразный контент: подборки лучших моделей (конечно же, со ссылками на карточки товаров в интернет-магазине), конкретные примеры их использования, сравнения с другими товарами, подробные описания, фотографии, видео и т.д.
В этом случае собранная информация поможет создавать экспертный контент, не только вызывающий доверие пользователей, но и действительно решающий их проблемы и отвечающий на их вопросы ещё до того, как покупатели о них подумают. Если же подобные руководства готовить для отдельных продуктов, это может не только сподвигнуть клиентов к совершению покупки, но и сократить количество возвратов товара и число обращений в службу поддержку.
Вопросы – всего лишь один из многочисленных типов информации, которую вы можете собирать с разных сайтов. XPath в связке с краулером можно использовать для извлечения любых общедоступных данных, будь это вопросы, отзывы, посты или что-то ещё. С помощью этого способа вы можете быстро собирать любую информацию – причем, получать её в удобной для дальнейшей работы форме. А это многого стоит как в SEO-продвижении, так и в контент-маркетинге и многих других областях.



